Karaoke for Deepfakes
A service for people to generate deepfake content. Through the performative and controlled medium of a karaoke booth, people can embody their heroes.
Category: Interactive installation, generative video, research
Instructor: Jennifer Rodenhouse
Year: 2019
Research
What’s a Deepfake?
An AI-generated video that replaces a face in one video with another face.
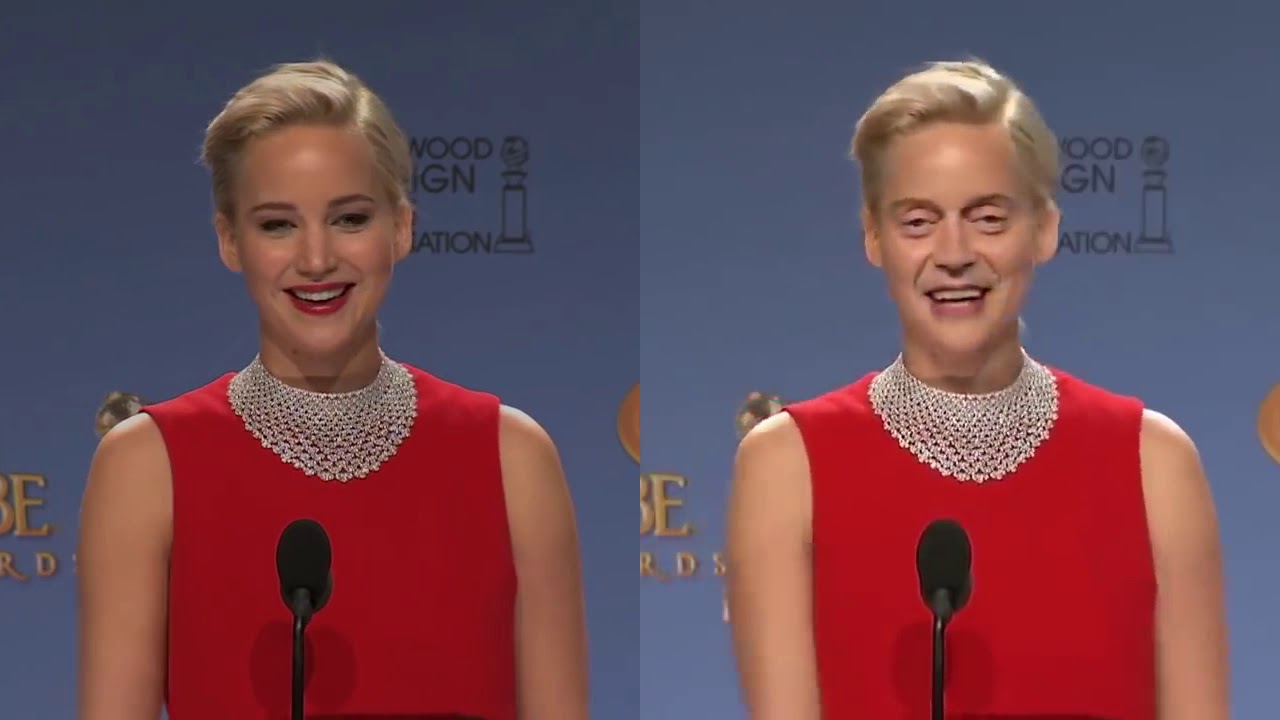
DeepFaceLab
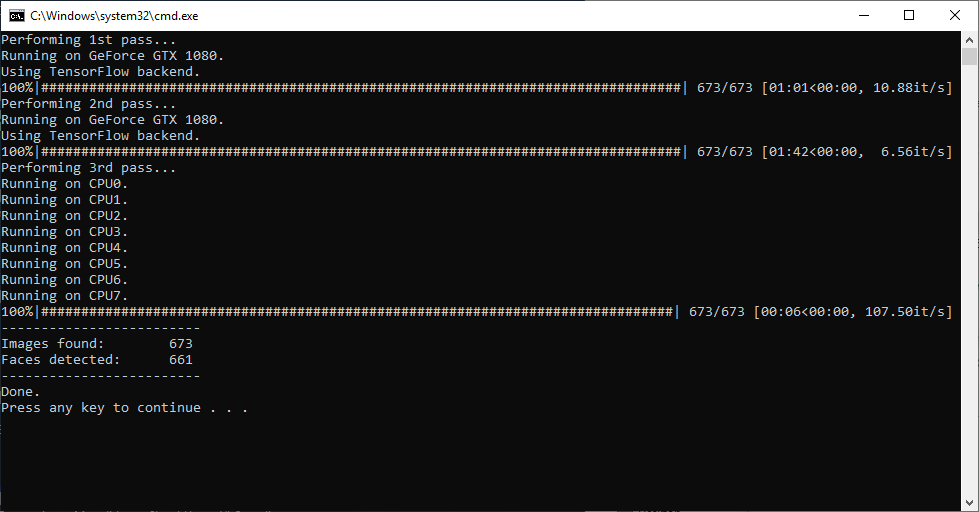
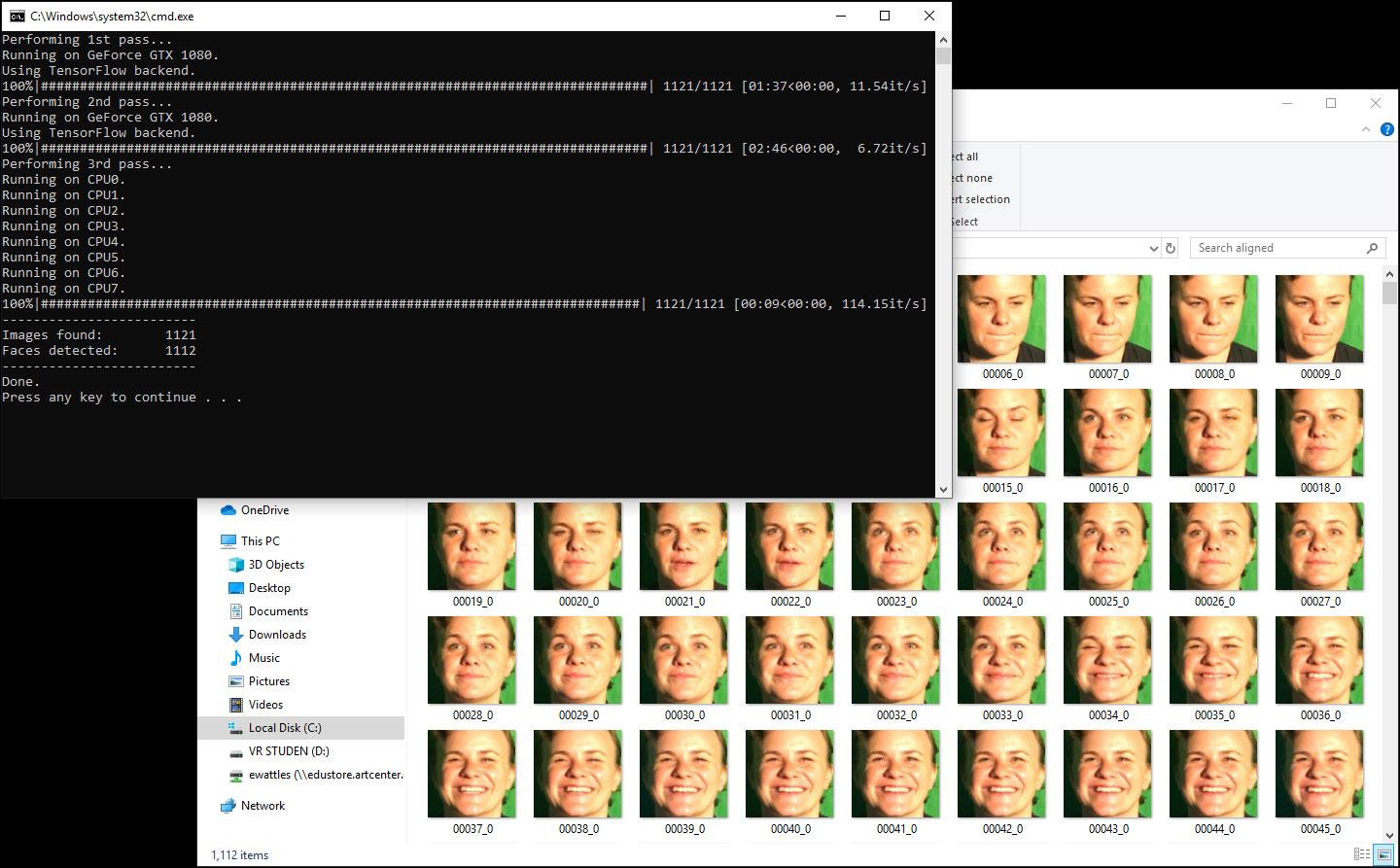
DeepFaceLab is the program I used, and there was a steep barrier to entry as it is definitely not consumer-ready software. It’s Windows-only. It isn’t well documented. There isn’t a GUI. It’s just a series of command-line scripts in a folder, each with an obscure list of text-only settings.
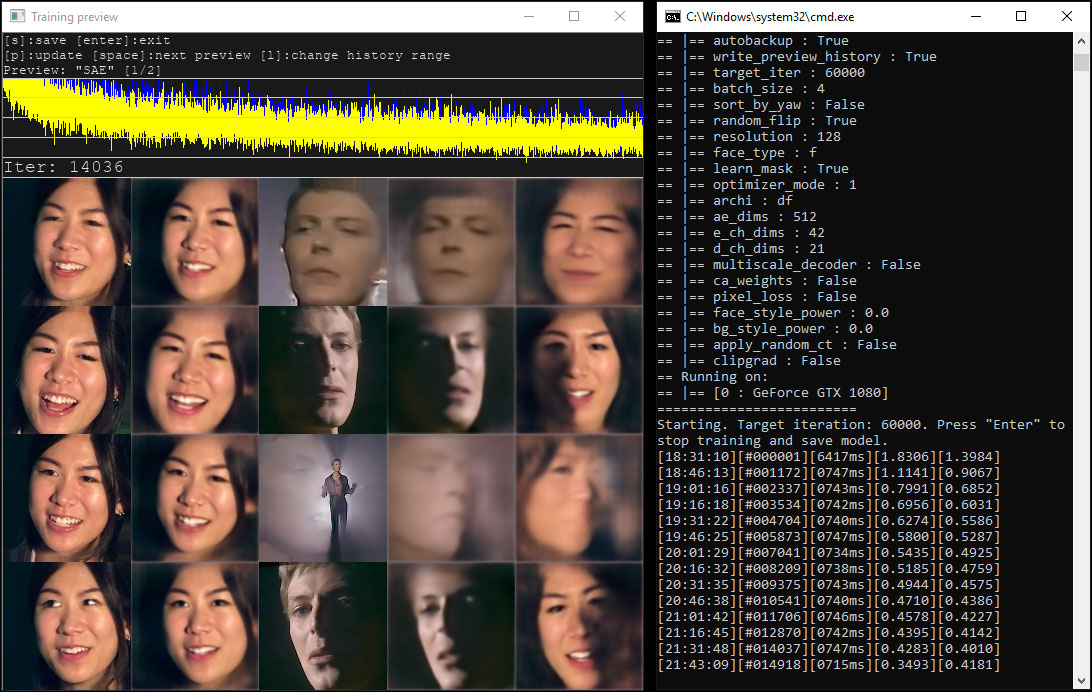 The windows you’ll see when training your AI model.
The windows you’ll see when training your AI model.
Data Collection
To make a deepfake, you need 2 sources of video, a few minutes each. Each face should be clearly visible, and each subject should be moving their head to multiple angles, making different expressions, and moving their mouth in different positions. The AI will build a model that will try to “match” the features of one face with another, based on its angle and expression.
 Source + Destination = Result (example videos in DeepFaceLab)
Source + Destination = Result (example videos in DeepFaceLab)
Requirements for Making a Good Deepfake Video
Think of these as design guidelines:
 2 videos, ~1-2 min each
2 videos, ~1-2 min each
 Clearly visible faces
Clearly visible faces
 Multiple expressions
Multiple expressions
 Multiple angles
Multiple angles
Visual Pattern
Most deepfakes people make are of celebrities/politicians/public figures because it’s easy to find source video that meets the above requirements.
I found that the best type of video content to use are interviews and keynotes/TED talks.
 r/GifFakes is a popular deepfake repository.
r/GifFakes is a popular deepfake repository.
Fake It Til You Make It
Graduation is stressful. By deepfaking myself into current-day heroes of design and technology, could I deepfake my way to success?
Raw Video
I chose a video of Tim Cook giving a presention as the destination video, and myself giving a presentation as the source video.
 Source: me giving a class presentation.
Source: me giving a class presentation.
 Destination: Tim Cook giving an Apple presentation.
Destination: Tim Cook giving an Apple presentation.
Video Processing
Video is a sequence of still images, but all you really need are the faces. DeepFaceLab provides scripts breaking up video frames, analyzing the faces in each frame, then cropping images accordingly.
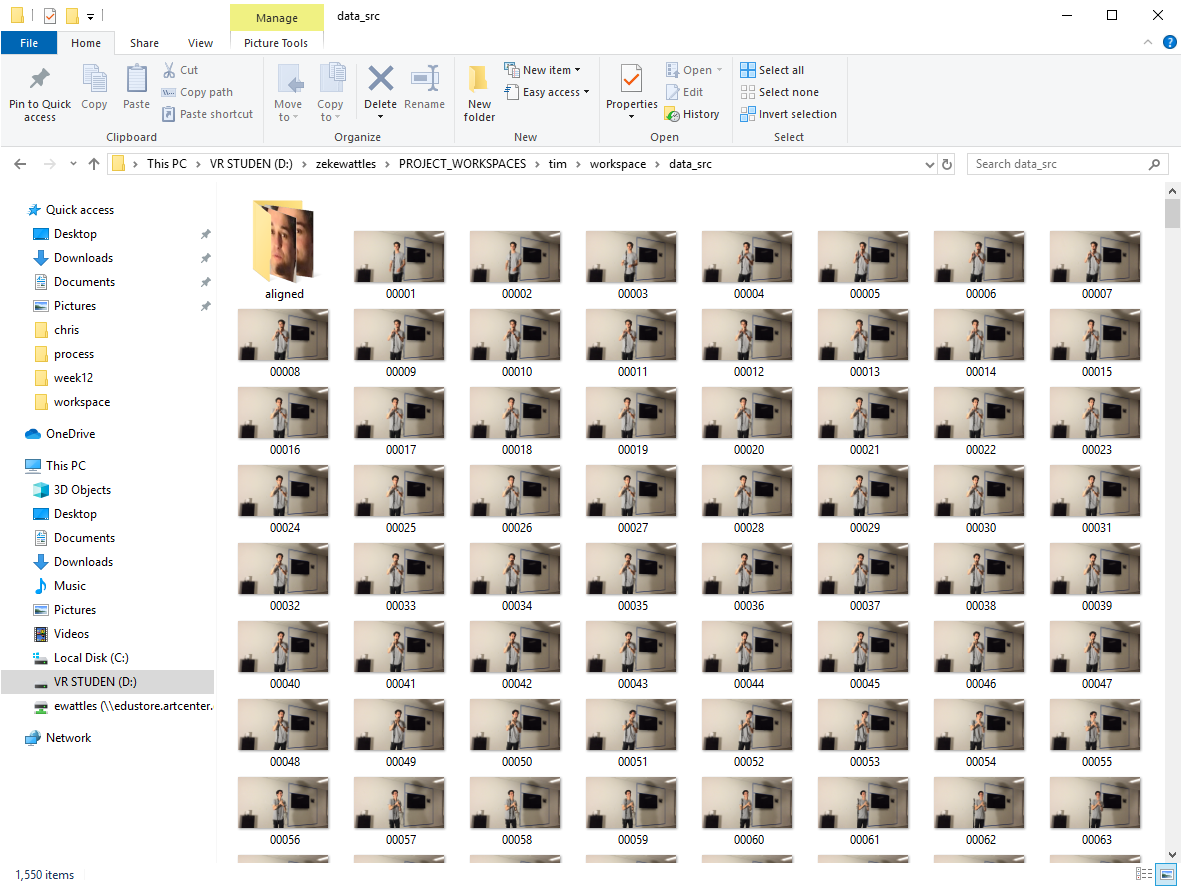
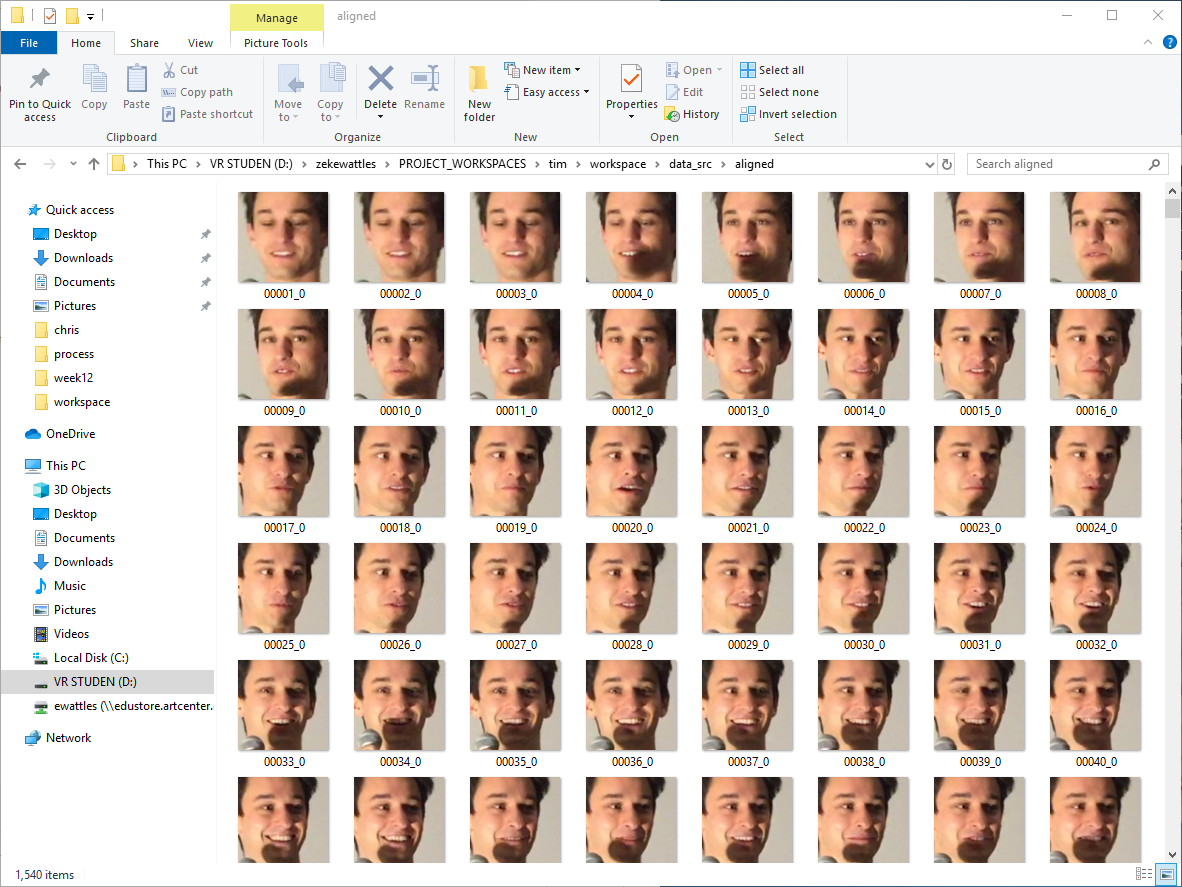
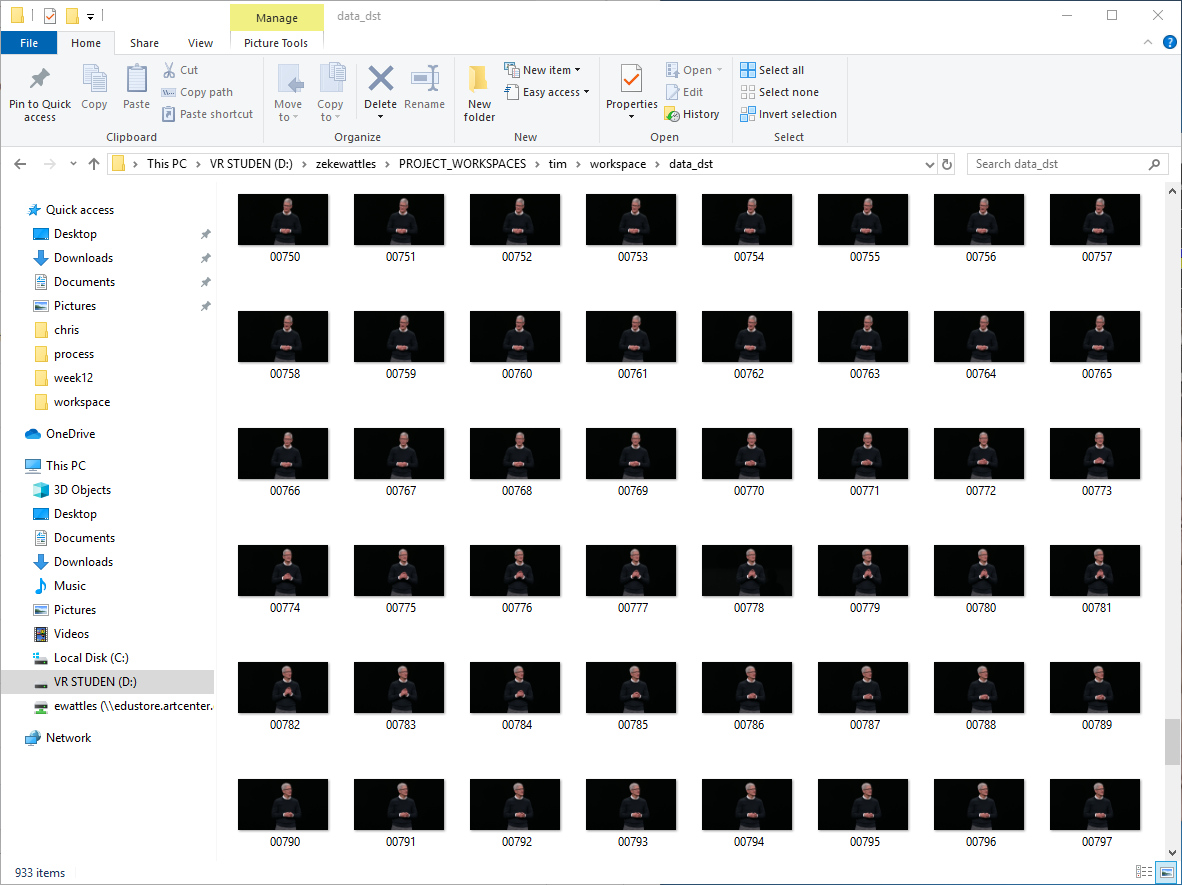
Training
Now, the AI has to “train a model.” We teach it how to identify the facial features one two facial datasets by giving it as large a variety as possible: a variety of expressions, mouth movements, and angles. Later, it will try to re-build the face of the “destination” video. The AI is learning to sketch from memory, and its memory improves over time.
24+ hours and 80,000+ iterations later, I had my results.
Results
Proposal
Design Problem
Deepfake videos are almost always celebrities or politicians because it’s easy to find the right type of video content of them, and there’s often a level of assumed deception or trickery involved.
 Source: Buzzfeed
Source: Buzzfeed
Key Questions
How can we democratize this content more while increasing deepfake literacy?
How do you set up an installation to generate the right kind of video content to deepfake anyone?
How do you diversify the content that’s deepfakes — not just celebrities, porn or politicians — and build consent into the process?
Our Solution Must:
Keep someone in front of a camera for 1-2 minutes.
Have them talk, move their head multiple angles, and make multiple expressions.
Give people a reason to want to be deepfaked.
Solution
A karaoke booth for gathering deepfake content (that doesn’t record audio, just facial video).
Karaoke feels natural and performative, while meeting all of our requirements.

Execution
Concept: Heroes
What if anyone could deepfake themselves into their heroes, too?
Do deepfakes have to be about deception, or can you use it to honor your subject, too? Have you always wanted to become your heroes? Now you can.
Booth Prototype
My recording booth consisted of:
- A greenscreen
- A spotlight
- A short-throw projector for projecting karaoke videos
- A tripod for holding a camera
- An iPhone (used to record video)
- A stool (some used it, some didn’t)

User Test 1: Heroes Lyric Video
I created a sing-along video for “Heroes” and projected it moving around the wall with the assumption that it would help me capture a large variety of face angles.
However, after the test, the first thing Mikiko (my test subject) asked was: “can I pick my own song?”

User Test 2: Choose Your Own Song
Analysis
There was no significant improvement by using moving video over normal karaoke video — people still look around and move to the music. The scale of the projection also caused people to move their head more to scan lyrics.
Realization: what people actually sing is irrelevant. All you really need is video of their face.







The Deepfake Process
To summarize, here are the steps for making a deepfake:
- Record content
- Split video to frames
- Extract faces from “source” video
- Train AI model
- Merge faces to “destination” video
- Convert frames to video
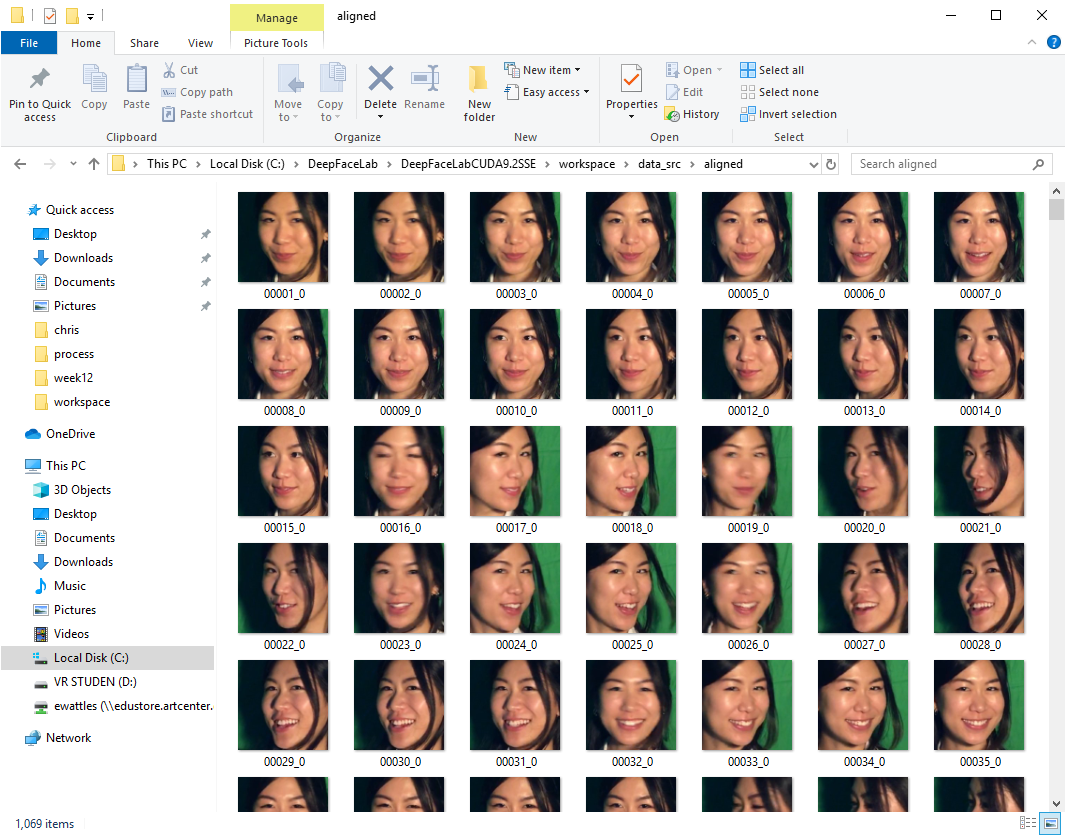
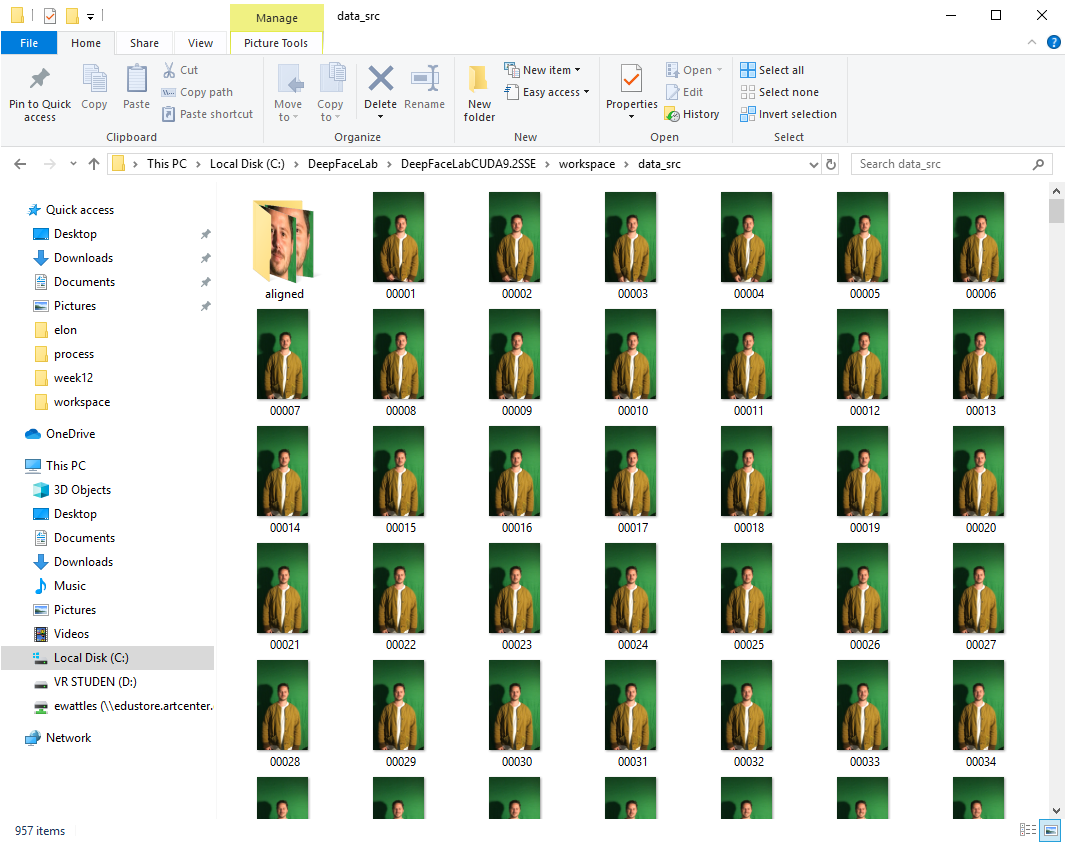
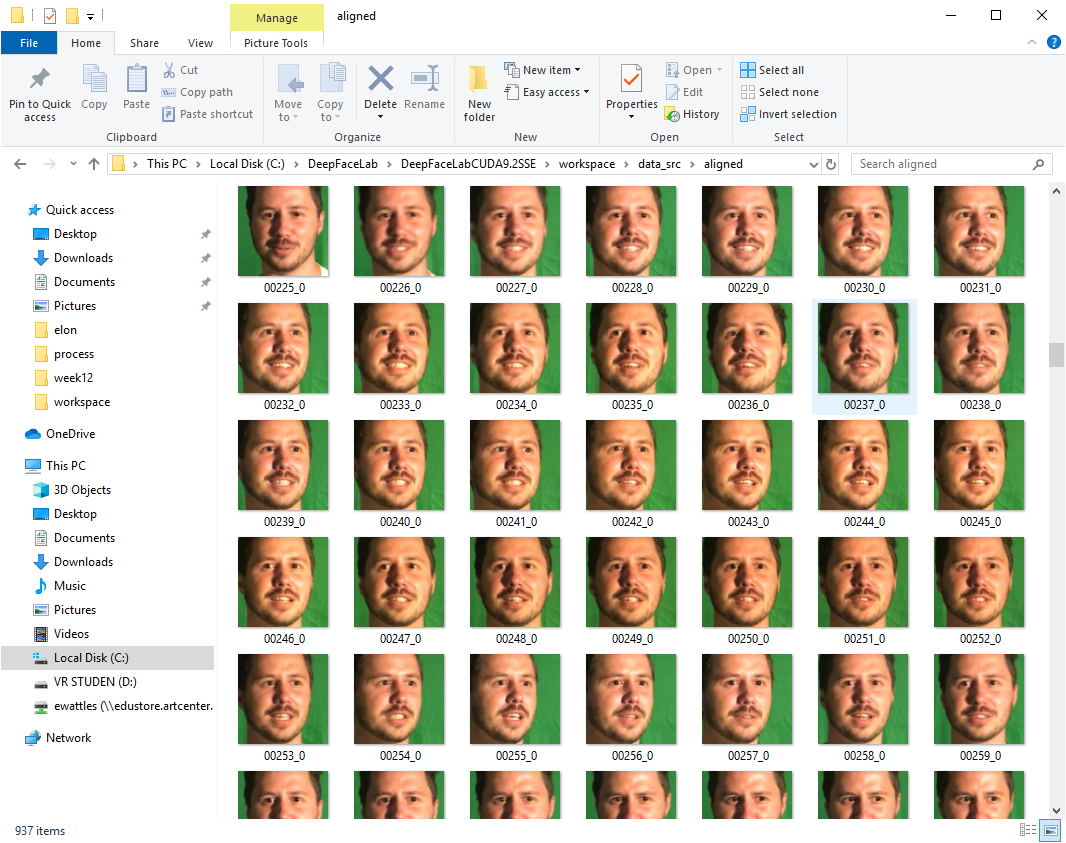
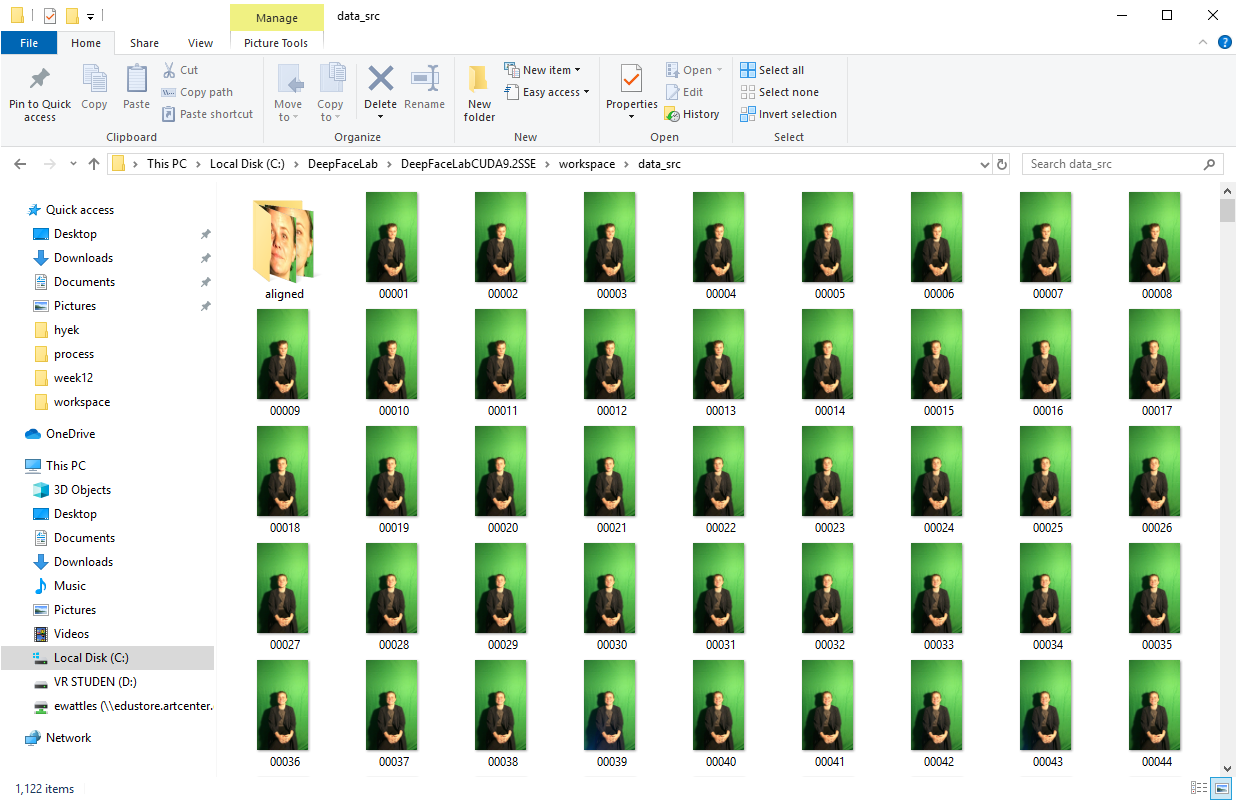
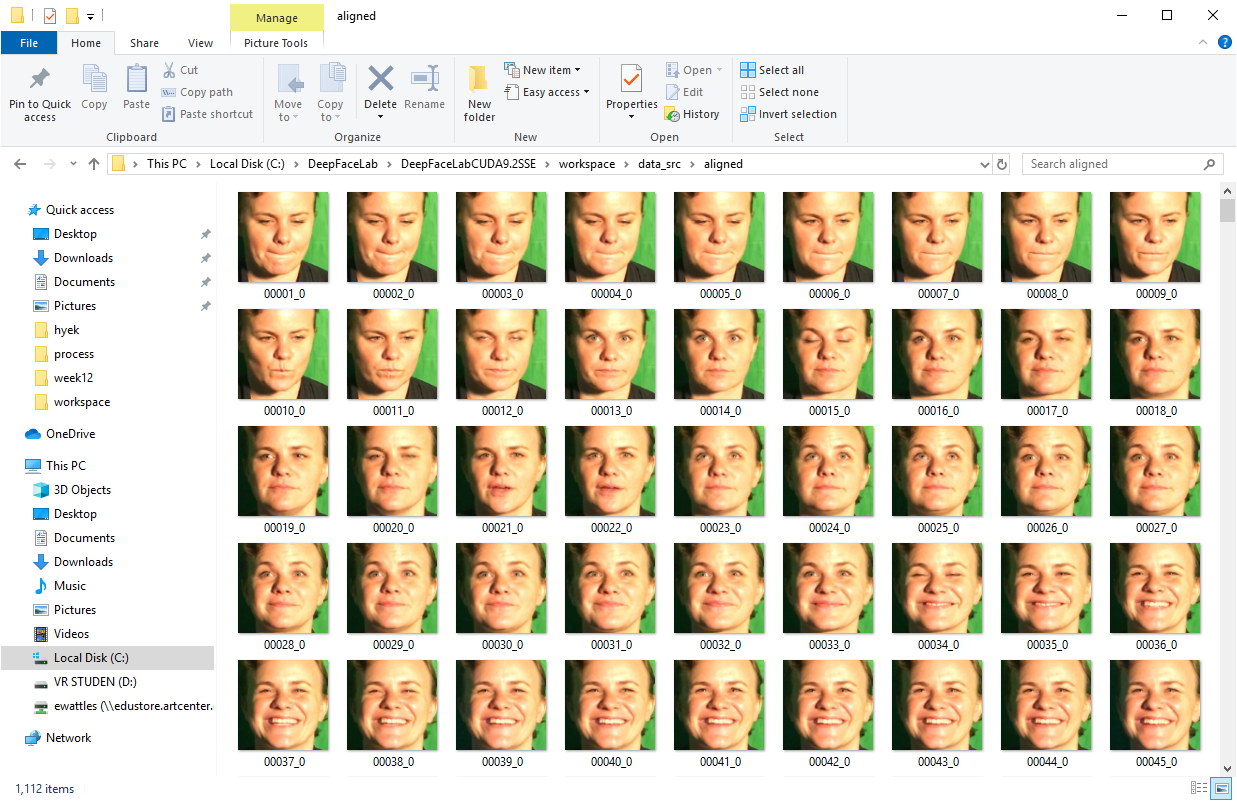
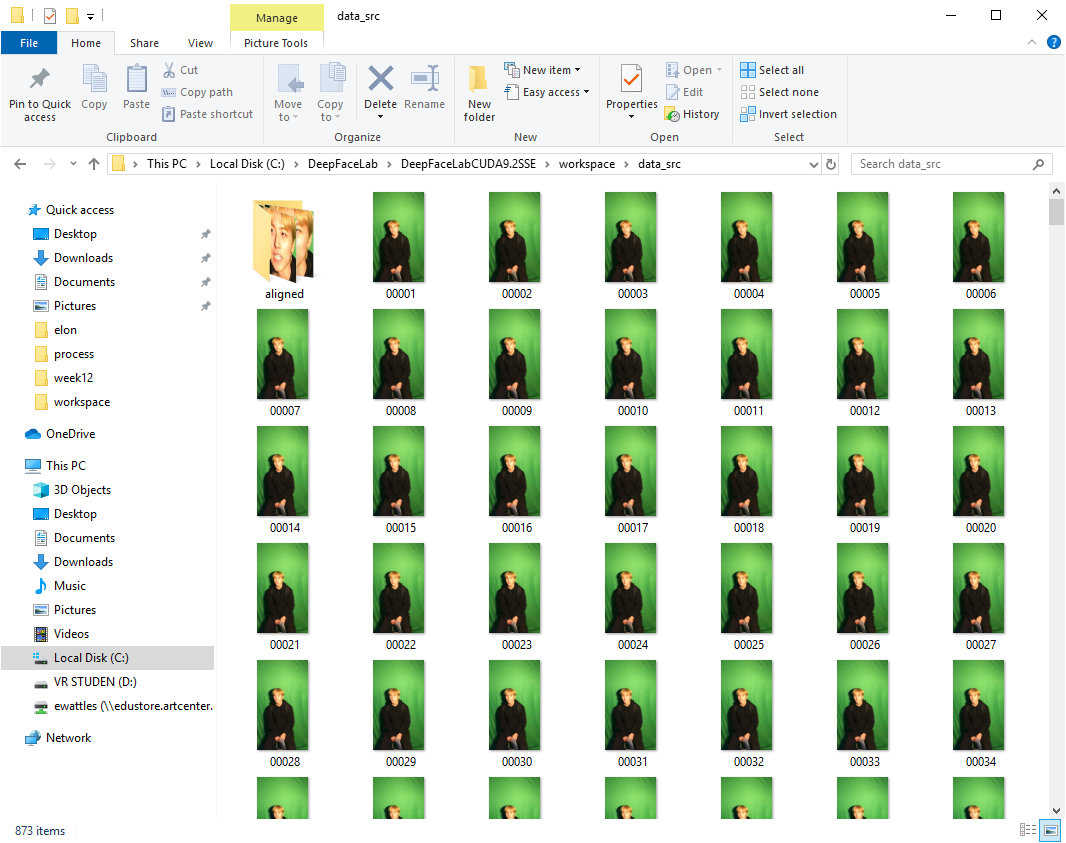
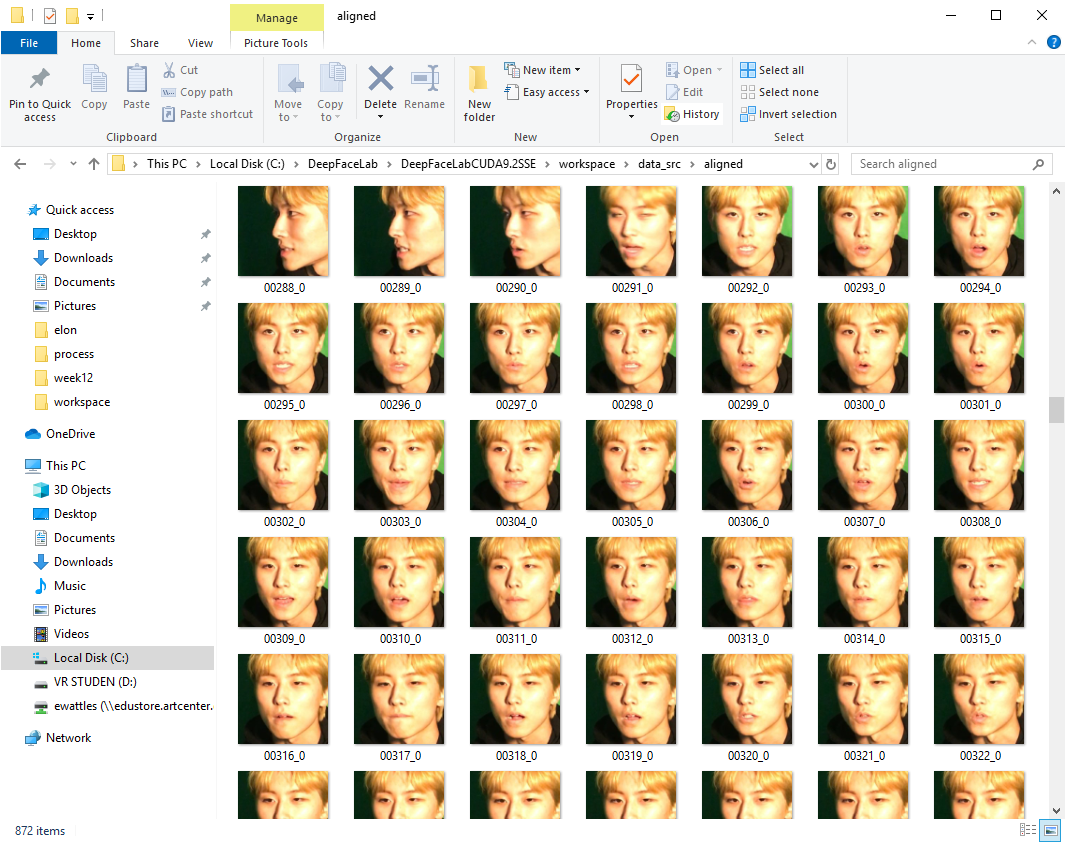
Results








What We’ve Learned
We’ve hit the limits of AI. Small faces and severe side angles don’t work, but other moments are convincing. The bad results are interesting, even beautiful.
To generate deepfakes, you need to curate the video that will be faked very carefully because many shots won’t work. This is why most deepfakes are very short and controlled.
The Future
A pop-up karaoke bar experience.
Come do karaoke and truly become a pop star. After the experience, users will be given both their video result and their dataset, giving them ownership of their facial data to use for further deepfaking if they wish.
The intention is to increase literacy about the process of deepfaking, and maintain a sense of humor about it — no one wants to hear more doomsday-speak about how deepfakes will be the end of democracy, right?
